原文: http://sqybi.com/blog/archives/322
前言
阅读本文,不需要太高深的编译原理知识,甚至不需要编译相关的知识。但是你至少要知道:
- 不管是exe可执行文件还是Linux下的程序,都是一些二进制码,我们称之为机器语言。这些二进制码的执行与系统以及CPU都有关。
- 大部分情况下,编译器是一种将高级语言翻译成机器语言的程序。而任何程序本身也是一些机器语言的二进制码。
- 无论是高级语言、汇编语言还是机器语言,实际上都是等价的,唯一有区别的是,越高级的语言写起来越容易(所以我们倾向于尽量多编写高级语言代码);同时,机器语言是可以直接运行的。
如果你觉得上面三条可以理解或者可以理解一部分,那么请继续阅读。另外,本文中提到的无论是编译的过程还是语言的分类甚至是一些例子,都可以看做是一个简化的模型。实际上,很少有一个exe程序就可以运行的编译器,现代的编译器都是十分复杂的。不过,考虑这些简化模型对我们没有任何坏处,它们和实际情况相差并不很大。
高级语言和机器语言
语言的所谓“高级”,实际上界定不是那么明确。不过我们可以确定的是:C++、Java、Python之流比汇编语言更高级,而汇编语言比机器语言更高级。
这里提到一个汇编语言和机器语言的区分。可能有些读者不明白这两个概念的区别,实际上很简单,汇编语言是我们会看到的那些MOV、JMP等命令组成的语言,而机器语言则纯粹是是各种01串。我想没有人会愿意写一个机器语言的程序——实际上,我们学校的计算机组成实验都是用Verilog HDL这种高级语言来完成的,而嵌入式原理实验也是用一种汇编语言完成的;即使是做处理器和单片机,也不会有人愿意去写机器语言,毕竟一大堆01串太坑爹了。
试想,让你用C++写一个从1输出到100的程序,几行代码就可以搞定;而汇编语言则可能需要几十行;机器语言呢,一大堆01000101110110101011111001……,看都看不懂。
但是上面也提到了,机器语言和高级语言的区别是,它可以直接运行。比如exe程序,实际上它内部存储的就是一些机器语言的二进制码,机器可以直接阅读这些二进制码并在处理器中运行它们(这里说的不是完全准确,比如.NET编译出的exe程序实际上是一段中间代码,由CLR解释成机器代码才能运行——不过这可以暂且忽略,就当作我说的是一个简化的模型)。当然程序的运行是依赖机器架构和系统的,不然Wine什么的也就没有用了(什么是Wine?WINE = WINE Is Not an Emulator!有趣的名称递归定义还有很多,不过与本文无关,请自行Google)。
而实际上,是机器架构不同还是系统不同,并不是我们考虑的问题。我们考虑的问题只是,一段代码在A机器上X系统下能否运行,换到B机器上Y系统下又能否运行。就算在A机器上X系统下能运行,如果换成了A机器和Y系统之后不能运行了,那对于我们这也可以看做两台不同的机器(也就是说,A机器和Y系统实际上就可以看做一个新的机器B)。所以之后的描述中,我们不考虑操作系统的情况,而是只考虑机器,我们编号为a、b等等,而它们上面可以运行的机器语言我们编号为A、B等等。
无论是机器语言还是高级语言,实际上都是代码。在之后的讨论中,我们应该将它们平等对待。
虽然机器语言的二进制码和高级语言的不同,它可以直接在机器上运行,但是对于编译过程,它们没有任何区别。
编译器
首先,编译器本身的功能是,将一种语言S的代码转化为一种语言T的代码。这里稍微了解编译器的读者可能有疑问了:我用的gcc之类的编译器,明明是把C语言代码编译成了一个exe程序,并不是把S语言的代码编译成了T语言的代码啊?如果你也有这个疑问,请重新阅读以上几段——我在前面已经提过了,“任何程序本身也是一些机器语言的二进制码”。也就是说,我们这里把机器语言也看作一种语言,只不过是很低级的语言;而编译器就可以将C语言这种高级语言S转化为机器语言这种低级语言T,恰好这种低级语言还是可以在机器t上直接运行的。
其次,大部分情况下,编译器自己也是一段程序,那么它也可以看做是一段代码。而编译器也会有它的源代码,这个源代码就是一种高级语言的代码,我们这时仍然叫它编译器。随便举个例子,对于gcc.exe,这个程序是一种机器语言A的代码,它可以直接在a机器上运行。而它的功能则是,将C语言的代码转化为机器语言A的代码(一个C语言的编译器),使得本身无法直接运行的C语言程序变得可以在a机器上运行。而在得到gcc.exe之前,我们一定也有一段代码,它是用来生成gcc.exe这个程序的,这段代码可能是一个高级语言的代码,比如汇编语言。那这时候,这段汇编语言的代码即使不能直接在电脑上运行,我们依然说这是一个C语言的编译器。
编译器的特征:
- 本身是一段代码,假设是A语言的代码,A可以是机器语言,也可以不是;
- 可以接收一段代码,假设是S语言的代码,S一般来说是高级语言,但理论上也可以不是;
- 可以将接收到的S语言代码在内部转换后输出一段代码,假设是T语言的代码,T有可能是机器语言,但也有可能是一种高级语言。
这样,一个编译器就可以被表示为A(S –> T),表示编译器本身的代码是A语言,可以接受一个S语言代码作为输入,同时产生相同功能的T语言代码作为输出。之后我们的编译器都会这么表示,请务必牢记。
编译器本质上也是一段代码,而功能上可以将一段代码等价地转化为另一段代码。
所以,我们用A(S –> T)表示一个编译器,这个编译器本身是由A语言写成的,它的功能是将S语言代码等价地转换为T语言代码。当A语言是机器语言的时候,这个编译器就是可以使用的。
自展
不知道读了之前的内容,你有没有这样一个疑问:既然编译器本身是一段代码,那么如果想编译一个编译器,就需要更早的编译器来进行编译操作。而编译这个更早的编译器还需要更更早的编译器——长此以往,第一个编译器是怎么产生的呢?难道是直接用机器语言书写的?
如果能这么想,那么你就猜对了。第一个编译器一定是用机器语言写出的。实际上,很久以前的程序员还在纸带上打孔呢,他们也照样乐在其中。机器语言只是很难书写,并不是不能书写。
但是,用这么难书写的语言写一个C++编译器,谁都不会愿意去干。所以,第一个编译器的功能一定是很简单的。而人们会用这很简单的编译器的语言,去写一个稍微复杂一些的编译器;然后再用这个新的编译器,去写一个更复杂的编译器;最终得到一个很复杂的编译器,比如C++编译器——好了,如果能够理解这个过程,那么你实际上几乎就理解了自展。
所谓自展,实际上就是用一个功能不太完善的编译器支持的语言写代码,然后放到这个编译器上去编译,产生一个比自己更完善的编译器的过程。用一个不太恰当的例子来描述,就是我们已经有了一个C语言的编译器,然后我们用C语言写一个C++的编译器代码,并用C语言编译器编译这个代码生成可以运行的C++编译器(之所以不太恰当,是因为C语言不是C++语言的严格子集)。
也就是说,我们有一个编译器A(C –> A),现在写一个编译器C(C++ –> A),将后者放入前者中进行编译,即A(C(C++ –> A) –> A),得到一个可以执行的编译器A(C++ –> A)。
自展过程,实际上就是用低级语言先实现一个简单的编译器,然后用这个编译器的语言再去编写一个更高级的编译器——这个新编译器是旧编译器的扩展——的过程。
交叉编译
交叉编译这个概念,没有自展这个概念那么准确。所以先看一个问题:如果你想写一个手机系统上的程序,你会怎么做呢?我们可能会想到,开发一个手机上的编译器,然后把程序放到上面编译成手机可以运行的机器代码。但是这样就有一个很大的问题了,那就是手机的运行速度和电脑相比十分缓慢(虽然现在手机的CPU已经很强悍了,但是手机的内存一向很小,不太足以运行编译器)。
实际上,在现实中我们的做法是,在电脑上完成编译过程,然后直接把在手机上可以运行的机器代码拷贝到手机内。这样就不受限于编译时手机的内存和CPU限制了。这样一个过程,就叫做交叉编译。
当然交叉编译也有其它的应用,比如有时候我们也需要在一台电脑a上生成另外一台电脑b上同一个语言的编译器,比如在Windows下编译一个Linux的编译器。这个问题比前面的问题还要多一步编译操作,我们不妨在后面的讨论中将这两个问题称作问题1(前者)和问题2(后者)。
为了方便起见,我们把这两个问题用之前的表示方法来书写一下:
首先,将电脑看做是机器a,手机看作是机器b。我们现在手里拥有的是某语言S在a机器上的编译器A(S –> A)。对于问题1,我们需要最终生成一个在a机器上编译b机器代码的编译器,即A(S –> B)。而对于问题2,我们则是需要一个在b机器上生成b机器代码的编译器,B(S –> B)。
而我们可以做到的是,用高级语言S写一个自身的编译器(可以是a机器的也可以是b机器的,不过这个问题中只有后者会被用到),即S(S –> B)。
好,现在我们就有了两个代码,A(S –> A)和S(S –> B),其中只有第一个代码是可以在a机器上运行的。我们要从这两个代码中得到两个新的代码,那就是A(S –> B)和B(S –> B)。
首先先考虑如何得到一个A(S –> B),即一个在a机器上运行的可以将S语言代码编译为b机器代码的编译器。
其实写成现在的形式,这一点如何做到已经很简单了。那就是将S(S –> B)放入A(S –> A)中编译,即A(S(S –> B) –> A),这样就可以得到A(S –> B)。这一步因为使用的编译器是A(S –> A),所以只需要在A机器上执行。
这时,可以发现第一个问题已经解决了。我们这时就可以利用得到的A(S –> B)在a机器(电脑)上编译b机器(手机)的代码了。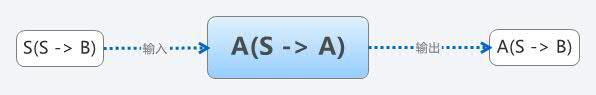
然后再考虑如何得到一个B(S –> B)。
可以看到,我们之前一步的时候有了一个A(S –> B),而最开始还拥有一个S(S –> B)。这样,我们只需要将S(S –> B)放入A(S –> B)中编译,即A(S(S –> B) –> B),这样就可以得到一个B(S –> B)了。
这样,我们用前一步得到的编译器A(S –> B),在a机器(Windows)上运行,又得到了一个新的编译器B(S –> B),它可以在b机器(Linux)下编译b机器(Linux)的代码。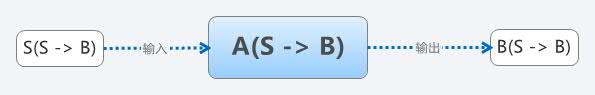
可以看到,我们从最开始的编译器A(S –> A)和代码S(S –> B)得到最终代码B(S –> B)的过程中,所有的步骤都是在A机器上运行的,完全没有用到B机器。这就是交叉编译的有趣之处!使用交叉编译,可以在很多情况下省去不少的麻烦。
另外解释一个问题,为什么不直接编写一个A(S –> B)?因为A是机器代码,而之前也提到过了,“我们倾向于尽量多书写高级语言代码”,因为机器语言十分难以理解和书写。所以,我们写了一个高级语言代码S(S –> B),将它放到已有的A(S –> A)上去编译(为什么是已有的?这个问题实际上不需要回答,因为这里假设a机器是一台很常用的机器(比如安装了Windows系统的PC机),所以A(S –> A)是一个很普通的编译器,它的存在性无需证明;A(S –> A)的书写可以利用之前提到的自展完成),最终得到了一个需要的B(S –> B)。
如果看不太懂交叉编译的过程的话,可以暂且把a机器当作一个安装了Windows的PC机,把b机器当作一台手机或者一个装了Linux的PC机,然后再带着这个理解重新阅读整个过程。
实际上,交叉编译解决的两个问题分别都只需要一步操作,所以交叉编译没有听起来那么复杂!不要自己吓到自己就好了~
就这些,没了。