Erlang编程规则和约定
原文地址:http://www.erlang.se/doc/programming_rules.shtml
Purpose
本文列出了在使用Erlang编写软件时,一些需要考虑的编程细节,而不是独立于Erlang之外的编程规范或者软件设计流程描述。
Structure and Erlang Terminology
Erlang系统由模块(module)组成,模块由函数(function)和属性(attribute)组成。
函数:已导出函数可被其它模块调用(Module:Function/ArgsNum)、未导出函数只能在本模块调用(Function/ArgsNum)。
属性:放置在模块的开头,以-开头(-module -export…)。
一个Erlang应用是由一到多个Erlang进程组成的,进程通过调用多个模块的多个函数来完成工作(The work in a system designed using Erlang is done by processes. A process is a job which can use functions in many modules.)。
Erlang进程通过发送和接收消息(message)来进行通信,接收者(进程)可以选择性地接收被发送给它的消息,未被接收的消息会存在于接收者的信箱里,直到接受者准备接收它们(或者接收者主动把它们抛弃掉)。
Erlang进程通过建立链接(link)来监督另一个Erlang进程,当进程终止时会自动向与其链接的进程发送退出信号(exit signal),接收到退出信号的进程默认行为是终止自己并且继续向已链接线程传播退出信号。进程可以通过捕获退出信号来改变此默认行为,这会将退出信号转换成消息。
纯函数(pure function)是指当传递给某函数的参数相同时,其值(return)不变。
SW Engineering Principles
尽可能少的从模块中导出函数
模块是Erlang系统的基本结构,模块中可以包含多个函数,只有被导出的函数才能在模块外被调用。
从模块外部看,一个模块的复杂度取决于这个模块被导出函数的数量,因为模块的使用者只需要理解从模块中导出的函数,导出几十个函数的模块比只导出一两个函数的模块更难以理解。
另外,当模块中的代码调整的时候,只要保证外部接口不变,模块功能就不会受影响。
减少模块之间的依赖
一个模块的功能实现依赖越多的其它模块,这个模块越难维护,因为每次对模块的接口函数进行修改,都必须检查并修改使用该模块接口的代码,减少模块之间的依赖可以简化维护过程。
理想模块之间的依赖性应该是树形结构,而不是循环结构。
树形结构: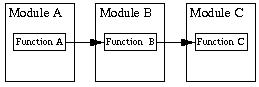
循环结构: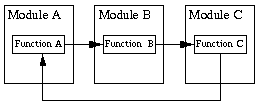
将常用代码放在库中
库是某功能相关函数的集合,应该尽力确保库包含的函数是相同类型的。
例如,lists库只包含用于操作列表的函数,易于使用和维护;假如lists_and_maths库既包含操作列表的函数,又包含数学运算的函数,是一个非常糟糕的设计。
最好的库函数应该是没有副作用的,因为具有副作用函数的库限制了它的可重用性。
将“脏”代码分离到单独的模块中
通常,可以通过混合使用干净和脏的代码来解决问题,但应该将干净和脏的代码分离成不同的模块。
在编程过程中,应该试图最大化干净代码的量和最小化脏代码的量。隔离脏代码的同时,并以注释或者其它方式记录脏代码的副作用和问题。
脏代码(包括并不限于):
1.依赖进程字典erlang:put/1, erlang:get/1
2.将erlang:process_info/1用于奇怪的用途
3.做任何不应该做(但又必须做)的事情
不要假设调用者会对函数的结果做出什么行为
假设调用者使用一些无效的参数调用函数do_somethins/1,do_somethins/1函数的实现者不应该假设当参数无效时函数的调用者希望发生什么。
1 | %% 错误的 |
对于错误的写法,函数的异常信息总是打印到标准输出;而正确的写法,函数只应将错误描述符返回给调用者,至于如何处理此错误描述符由调用者决定。
可以在模块中添加error_report/1函数,调用者通过调用error_report/1可以将错误描述符转换为可打印的字符串,并在需要时打印。但是无论如何,关于对函数返回值做出什么行为,都应该由调用者决定。
避免“面向复制粘贴编程”(Abstract out common patterns of code or behavior)
如果代码或者代码模式相同的函数需要在多个地方使用,那就在公共函数中实现并封装这个函数;而不是将同一份代码(代码模式)复制到两个不同的地方,复制的代码需要更多的精力维护。
如果在代码中两个或者多个位置看到类似的代码,那么值得花时间看看是否能稍微改变下问题,通过写入少量的代码来描述之间的区别,将其合并成一个公共函数。
Top-Down
使用自上而下的方式开发,而不是自下而上(从细节出开始),自上而下是一种连续逼近细节的好方法(终止于已存在的原始函数)。
自上而下的好处在于当完成了顶层代码就知道了底层代码应该被设计成什么样(The code will be independent of representation since the representation is not known when the higher levels of code are designed.)。
不要过早优化代码
不要在开发的第一阶段优化代码,首先应该保证功能正确,然后(必要的情况下)提高代码的执行效率(同时保证功能正确).
最少惊讶原则(Use the principle of “least astonishment”)
应该以正常的方式对操作做出响应,调用者(操作者)应当能够预测出它们做某事会导致某种结果,而不应对结果感到惊讶。
这受到模块的一致性影响,多个模块组成的系统中各模块都采用类似的方式处理问题优于各模块采用不同的方式处理问题。
如果你对某个函数感到惊讶,可能是该函数解决了错误的问题或者该函数的命名有问题。
尽量消除副作用
Erlang有些函数是有副作用的,它们会对环境做出永久性更改,在调用这些使用了有副作用函数的函数必须要知道进程的确切状态。
尽可能不要使用有副作用的函数,最大化纯函数(pure function)的数量。
对于有副作用的函数要明确记录其副作用。
使用有副作用的函数时要更加小心。
不要让私有数据结构”泄漏”出模块
1 | -module(queue). |
使用上述模块需要这样调用:
1 | NewQ = [], % 不要这样做 |
更好的方法是:
1 | -module(queue). |
使用上述模块需要这样调用
1 | NewQ = queue:init(), |
优点在于调用者无需知道queue的结构是个列表,无论是后期维护还是修改,都更加方便。
如果要获取queue的长度,可以这样:
1 | -module(queue). |
调用者应该通过queue:len(Queue)来获取长度,而不是length(Queue)。
抽象出模块内部细节的做法可以在我们改变内部结构时,而无需改变调用者的代码。
e.g.queue模块进行了如下修改不会对调用者产生影响:
1 | -module(queue). |
尽可能提高代码的确定性
确定性代码是指当以相同的方式运行程序,无论多少次其结果应该是一样的。而非确定性代码则会在每次运行时产生不同的结果。出于易于调试的目的,提高代码的确定性有助于错误的重现。
假设一个进程要启动五个并行的进程(启动顺序不重要),然后检查它们是否正确启动。可以先把五个进程都运行起来,然后检查它们是否正确启动;但更好的方法是一次只启动一个,并且在下一个启动之前检查前一个是否正确启动。
不要“防守”
防御性编程是指检查系统输入的数据是否正确,系统应该只使用一小部分代码执行输入数据的检查(通常在数据首次进入系统时完成),而大多数代码应该假定输入的数据是正确的。
1 | get_server_usage_info(Option, AsciiPid) -> |
如果输入的参数不符合Option :: all | normal,就应该让函数崩溃,从而告知调用者。
使用设备驱动程序隔离硬件接口(Isolate hardware interfaces with a device driver)
系统应该通过使用设备驱动程序来与硬件接口隔离。通过设备驱动程序使硬件接口看起来更像Erlang的进程,从而硬件可以接收和发送正常的Erlang消息,并在发生错误时以常规方式抛出。
在同一个函数中实现X操作和撤销X操作(Do and undo things in the same function)
假设我们在程序中打开一个文件,做了一些操作后,关闭这个文件,那应该这样写:
1 | do_something_with(File) -> |
而不应该这样:
1 | do_something_with(File) -> |
Error Handling
分离错误处理代码和正常代码
处理异常的代码不应该混淆正常情况的代码,在编写过程中,应该只编写正常情况的代码,如果代码失败,就应该尽快崩溃进程和报告错误,不要尝试修复错误后继续运行。
识别错误内核(Identify the error kernel)
系统设计的基本要素之一就是识别出系统哪部分必须是正确的,哪部分可以是错误的。
在常规系统设计中,系统的内核被假定为必须是正确的,而所有用户的操作不必须是正确的,即使用户操作出现故障也不应该影响整个系统的正确和完整。
系统设计的第一部分就是确定系统中必须正确的部分,称之为错误内核(the error kernel),通常情况下,错误内核应该具有某种存储至数据库的实时存储器。
Processes, Servers and Messages
保持模块的单一性
单个进程的代码应该只存在于一个模块中,进程可以调用任何库函数。进程“顶层循环”(top loop)的代码应该只存在于单独模块中。如果进程的“顶层循环”代码存在于多个模块,这会导致控制流程非常困难。
一个模块中也不应该存在多个进程执行的代码,包含多个进程的代码的模块可能非常难以理解。
每个单独进程的代码应该分解成一个单独的模块。
使用进程组建系统(Use processes for structuring the system)
进程的Erlang系统的组成元素,如果可以使用函数调用实现的功能,不要使用进程和消息传递。
注册进程
进程应该使用模块名作为进程注册名,这样会很容易找到进程所在的代码。
如果某进程会存在很长时间,那就应该为其注册一个进程名。
为每个并发活动确定一个并行进程
当犹豫该使用顺序或者并行来实现某功能时,应该使用功能内在结构所暗示的结构,规则如下:
Use one parallel process to model each truly concurrent activity in the real world.
使用并行的进程来模拟真实世界里每个真正的并发活动。
并行进程的数量和真实并发活动的数量存在一一对应,这样程序会很容易理解。
每个进程只应该扮演一个角色
尽可能的,进程在系统中应该只扮演一个角色,它可以是客户端也可以是服务器,但不应该组合这个角色。
进程可以扮演以下角色(包括但不限于):
Supervisor:监视其它进程;
Worker:一个正常的可能出错的工作进程;
Trusted Worker:不应该出错的工作进程。
尽可能使用通用程序实现服务器和协议处理
在大多数情况下,使用通用服务器程序会大大简化系统的总体结构,例如标准库中实现的generic。
对于大多数协议处理程序也是一样的。
标记消息(Tag messages)
所有在Erlang进程间传递的消息都应该带标记,这样接收者不需要依赖消息匹配的顺序,并且更加容易添加新的消息类型。
1 | %% 不要这样: |
丢弃未知的消息
1 | main_loop() -> |
每个接收者都应该有一个保护,用于丢弃无法识别的消息类型(如果一直不丢弃,信箱会爆)。
使用尾递归
1 | %% 错误的方法: |
所有的接收者都应该使用尾递归,否则会耗尽内存。
也可以使用标准库自带的通用服务器,来避免这样的问题。
接口函数
尽可能的使用接口函数,避免直接发送消息,封装消息传递到接口函数,从而在接口函数中发送消息。
消息协议应该是内部的,对其它模块隐藏的。
1 | -module(fileserver). |
超时
在receive语句中使用after要小心,确保在消息到达后才会执行after。
Be careful when using after in receive statements. Make sure that you handle the case when the message arrives later.
捕获退出信号
尽可能少的去捕获进程的退出信号,进程可以捕获退出信号,也可以不捕获,但是捕获退出信号后转换成其它类型的消息继续传递通常是很糟糕的做法。
Various Erlang Specific Conventions
使用record结构
record是带标记的元组,类似于C的struct和Pascal的record。
如果record要在多个模块中使用,应该将其定义在头文件(.hrl)中,并在模块中包含头文件,这样可以保证record结构的一致性。
如果record只在一个模块中使用,那么应该将其定义在模块的开头。
Erlang的record特性可用于确保多模块数据结构的一致性,因此在模块间传递数据结构时,record应由接口函数使用。
使用选择器(selector)和构造函数(constructor)
应该使用选择器和构造函数来管理record,而不应该使用匹配元组的方法匹配record
1 | demo() -> |
使用带标记(Tag)的返回值
1 | %% 错误的: |
使用catch和throw的时候要非常小心
Do not use catch and throw unless you know exactly what you are doing! Use catch and throw as little as possible.
当程序逻辑复杂或者有不可靠的输入的时候,catch和throw可能会很好用,例如导致错误的代码藏在深深的地方。
使用进程字典的时候要非常小心
Do not use get and put etc. unless you know exactly what you are doing! Use get and put etc. as little as possible.
需要使用进程字典的函数可以通过引入新的参数来重写
1 | %% 错误的: |
不要使用-import
在模块中使用-import会导致代码更难读,因为不能直接看到被调用的函数定义在哪个模块中。
可以使用Erlang的Xref工具(The Cross Reference Tool)查找模块间的依赖。
合理使用-export
区分导出函数的类型:
1.模块的用户接口
2.其它模块的接口函数
3.被导出但是只在模块内使用
1 | %% user interface |
Specific Lexical and Stylistic Conventions
不要编写嵌套过深的代码
嵌套代码是指case/if/receive语句中包含其它的case/if/receive语句。深度嵌套的代码(代码有一种向右偏移的趋势)是一种非常糟糕的编程风格,可读性非常差。
函数最好不要超过两个缩进级别,可以将函数划分成更短的函数来实现。
不要编写非常大的模块
一个模块最好不要超过400行,多个小模块比一个大模块要好得多。
不要写很长的行
一行不应超过80个字符。
1 | %% Erlang会自动连接跨行的字符串 |
变量名
虽然选择有意义的变量名很困难,但值得费脑筋。
如果变量名由多个单词组成,可使用_分割,或者驼峰命名法。
在与功能无关的变量名前添加_,不仅可以防止编译器警告,还能提高代码的可读性。
函数名
函数名应该与函数功能一致,它应该返回函数名暗示的参数种类,不应该让调用者感到惊讶。
解决同一问题的不同模块中的函数应该具有相同的名字,e.g.Module:module_info/0。
编写大量的不同的函数时,采用一种命名约定非常有用,e.g.名称前缀是is_的函数返回true | false。
1 | -spec is_XX() -> true | false. |
模块名
Erlang的模块名是全局的(没有模块中的模块)。当我们想模拟分层的模块结构时,可以通过具有相同模块前缀的模块集合来完成。
如果有多个模块来实现ISDN,可以分别命名为isdn_init isdn_partb isdn_...。
一致的编程风格
一致的编程风格能帮助理解代码。不同的开发者会使用不同的编程风格,包括缩进、换行等等。
例如{12,23,45}和{12, 23, 45}
一旦你采用了一种编程风格,保持下去,不要改变它。
在更大的开发项目中,应该在所有部分都使用相同的编程风格。
Documenting Code
Attribute code
1 | -revision('Revision: 1.14 '). |
在模块的开头添加合适的属性标记。
Provide references in the code to the specifications
Provide cross references in the code to any documents relevant to the understanding of the code. For example, if the code implements some communication protocol or hardware interface give an exact reference with document and page number to the documents that were used to write the code.
如果编写某功能参考了某文档,应该在代码中备注引用的文档以及页码。
Document all the errors
All errors should be listed together with an English description of what they mean in a separate document.
By errors we mean errors which have been detected by the system.
At a point in your program where you detect a logical error call the error logger thus:error_logger:error_msg(Format, {Descriptor, Arg1, Arg2, ....})
And make sure that the line {Descriptor, Arg1,…} is added to the error message documents.
记录所有的错误。
Document all the principle data structures in messages
Use tagged tuples as the principle data structure when sending messages between different parts of the system.
The record features of Erlang (introduced in Erlang versions 4.3 and thereafter) can be used to ensure cross module consistency of data structures.
An English description of all these data structure should be documented.
消息传递应使用元组结构,并添加标记{Tag, Arg}
Comments
注释应该简短,最好用英文书写。
关于模块的注释用%%%三个百分号。
关于函数的注释用%%两个百分号。
关于Erlang代码的注释用%一个百分号,且注释应该跟着具体的代码缩进。
1 | %% Comment about function |
Comment each function
一个函数的注释应该包含:
1.函数的功能
2.函数的参数结构以及有效参数域
3.如果函数实现了一个较为复杂的算法,要详细描述
4.函数可能产生故障的原因以及产生故障后的表现exit/1, throw/1, ErrorReturn
5.函数的全部副作用
Data structures
记录record结构中每个field的确切意义。
File headers, copyright
1 | %%%--------------------------------------------------------------------- |
在源文件的开头声明版权。
File headers, revision history
1 | %%%--------------------------------------------------------------------- |
在源文件的开头记录修改历史。
File Header, description
1 | %%%--------------------------------------------------------------------- |
模块头部应该有简短的描述,包括模块的功能以及导出的函数。
如果你知道任何关于这个模块的弱点、错误、会出问题的功能等等,用特殊注释的方式记录它们,而不应该隐藏它们。
Do not comment out old code - remove it
不要注释无用的代码,删除它。
Use a source code control system
使用源代码版本控制工具
SVN, git, RCS, CVS or Clearcase
The Most Common Mistakes
1.函数过长
2.深层嵌套
3.返回值不规范
4.函数名与功能不对应
5.无意义的变量名
6.在不需要使用进程时使用进程
7.使用不合适的数据结构
8.错误的备注或者没备注
9.代码不缩进
10.使用进程字典
11.不控制消息队列(信箱爆炸)