Go标准库encoding/json真的慢吗?
https://medium.com/a-journey-with-go/go-is-the-encoding-json-package-really-slow-62b64d54b148

Illustration created for “A Journey With Go”, made from the original Go Gopher, created by Renee French.
插图来自于“A Journey With Go”,由Go Gopher组织成员Renee French创作。
This article is based on Go 1.12.
Questions about the performance of the encoding/json package is a recurrent topic and multiple libraries like easyjson, jsoniter or ffjson are trying to address this issue. But is it really slow? Has it been improved?
本文基于Go 1.12。
关于标准库encoding/json性能差的问题在很多地方被讨论过,也有很多第三方库在尝试解决这个问题,比如easyjson,jsoniter和ffjson。但是标准库encoding/json真的慢吗?它一直都这么慢吗?
Evolution of the package
标准库encoding/json的进化之路
Let’s look first at the performance evolution of the library. I made a small makefile with a benchmark file in order to run it against all versions of go:
首先,通过一个简短的makefile文件和一段基准测试代码,我们看下在各个Go版本中,标准库encoding/json的性能表现。以下为基准测试代码:
1 | type JSON struct { |
The makefile creates a folder for each version of go, creates a container based on its docker image, and runs the benchmark. The results are compared in two ways:
- each version VS the last version of go 1.12
- each version VS the next version
makefile文件在不同的文件夹中基于不同版本的Go创建Docker镜像,在各镜像启动的容器中运行基准测试。将从以下两个维度进行性能对比:
- 比较Go各版本与1.12版本中标准库
encoding/json的性能差异 - 比较Go各版本与其下一个版本中标准库
encoding/json的性能差异
The first comparison allows us to check the evolution from a specific version against the last one, while the second analysis allows us to know which one brought the most improvements into the encoding/json package.
第一个维度的对比可以得到在特定版本的Go与1.12版本的Go中json序列化和反序列化的性能差异;第二个维度的对比可以得到在哪次Go版本升级中json序列化和反序列化发生了最大的性能提升。
Here are the most significant results:
测试结果如下:
- from 1.2.0 to 1.3.0, the time for each operation has reduced by ~25/35%:
- Go1.2至Go1.3的版本升级,序列化操作耗时减少了约28%,反序列化操作耗时减少了约35%
1 | name old time/op new time/op delta |
- from 1.6.0 to 1.7.0, the time for each operation has reduced by ~25/40%:
- Go1.6至Go1.7的版本升级,序列化操作耗时减少了约27%,反序列化操作耗时减少了约40%
1 | name old time/op new time/op delta |
- from 1.10.0 to 1.11.0, the memory allocation has reduced by ~25/60%:
- Go1.10至Go1.11的版本升级,序列化内存消耗减少了约60%,反序列化内存消耗减少了约25%
1 | name old alloc/op new alloc/op delta |
- from 1.11.0 to 1.12.0, the time for each operation has reduced by ~5/15%:
- Go1.11至Go1.12的版本升级,序列化操作耗时减少了约15%,反序列化操作耗时减少了约6%
1 | name old time/op new time/op delta |
The full report is available on github for Marshall and Unmarshall.
可以在这里看到完整的测试结果。
If we check from 1.2.0 to 1.12.0, the performances have significantly improved:
如果对比Go1.2与Go1.12,会发现标准库encoding/json的性能有显著提高,操作耗时减少了约69%/68%,内存消耗减少了约74%/29%:
1 | name old time/op new time/op delta |
The benchmark has been done with a simple struct. The deltas could be different with a different value to encode/decode things such as a map or an array or even a bigger struct.
该基准测试使用了较为简单的json结构。使用更加复杂的结构(例如:Map or Array)进行测试会导致各版本之间性能增幅与本文不同。
Dive into the code
速读源码
The best way to understand why it seems slower is to dive into the code. Here is the flow of the Marshal method in go 1.12:
想了解标准库性能较差的原因的最好的办法就是读源码,以下为Go1.12版本中json.Marshal函数的执行流程:
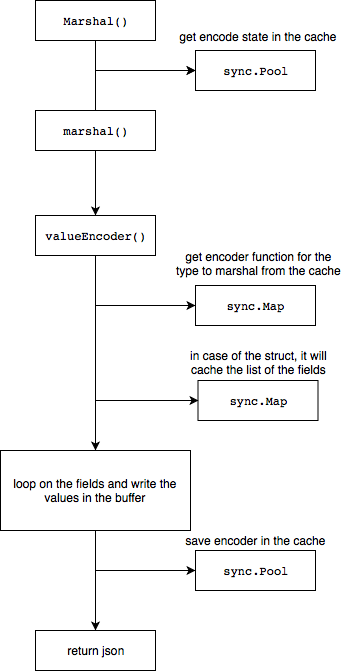
Now that we know the flow, let’s compare the code of the versions 1.10 and 1.12 since we have seen there was a huge improvement on the memory during the Marshal process. The first modification that we see is related to the first step of the flow when the encoder is retrieved from the cache:
在了解了json.Marshal函数的执行流程后,再来比较下在Go1.10和Go1.12版本中的json.Marshal函数在实现上有什么变化。通过之前的测试,可以发现从Go1.10至Go1.12版本中的json.Marshal函数的内存消耗上有了很大的改善。从源码的变化中可以发现在Go1.12版本中的json.Marshal函数添加了encoder(编码器)的内存缓存:
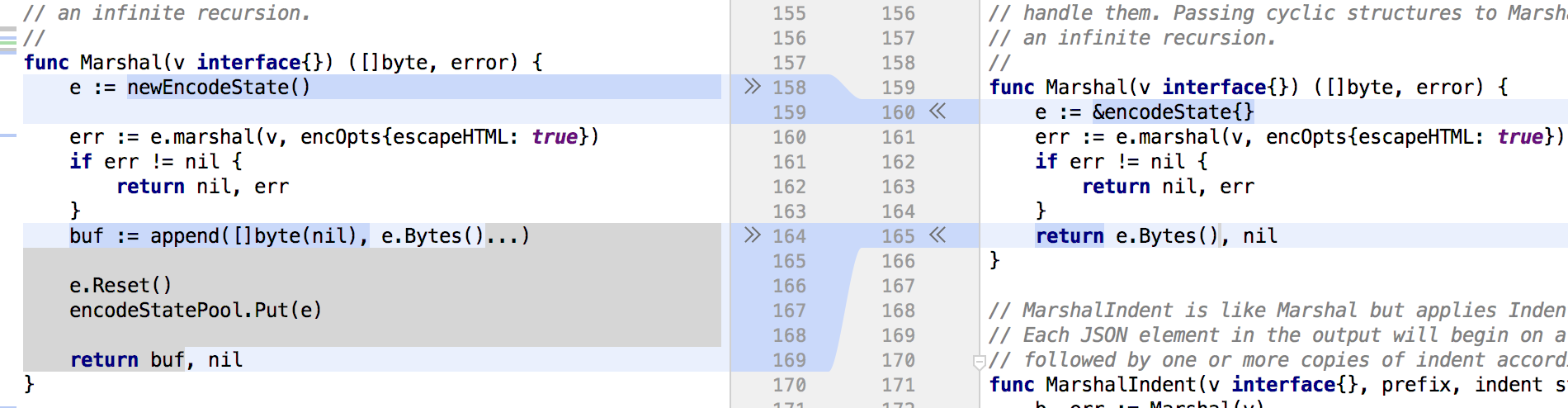
The sync.Pool has been added here in order to share the encoder and reduce the number of allocations. The method newEncodeState() already existed in 1.10 but was not used. To confirm that, we can just replace this piece of code in go 1.10 and check the new result:
在使用了sync.Pool缓存encoder后,json.Marshal函数极大地减少了内存分配操作。实际上newEncodeState()函数在Go1.10版本中就已经存在了,只不过没有被使用。为验证是添加了内存缓存带来了性能提升的猜想,可以在Go1.10版本中修改json.Marshal函数后,再进行测试:
1 | name old alloc/op new alloc/op delta |
In order to run the benchmark with the Go repository, just go to the folder of the lib and run:
可以直接在Go源码中,执行以下命令进行基准测试:
1 | go test encoding/json -bench=BenchmarkCodeMarshal -benchmem -count=10 -run=^$ |
As we can see, the impact of the sync package is huge and should be considered in your project when you allocate the same struct intensively.
结果和我们的猜想是一致的。是sync包给json.Marshal函数带来了性能提升。同样也给我们带来一点启发,当项目也有这种对同一个结构体进行大量的内存分配时,也可以通过添加内存缓存的方式提升性能。
Regarding the the Unmarshal method, here is the flow in go 1.12:
以下为Go1.12版本中,json.Unmarshal函数的执行流程:
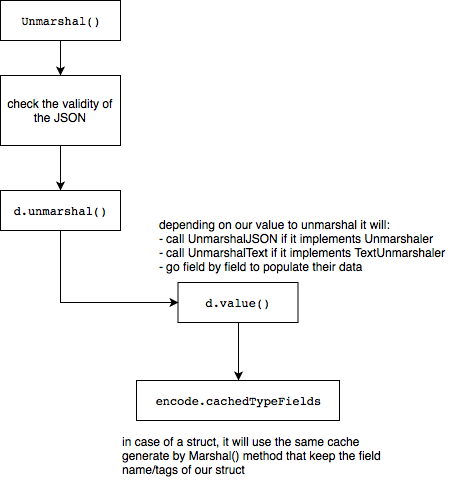
Each of the flows are pretty optimized with a cache strategy — thanks to sync package — and we can see that the part regarding the reflection and the iteration on each fields is the bottleneck of the package.json.Unmarshal函数同样使用sync.Pool缓存了decoder。
对于json序列化和反序列化而言,其性能瓶颈是迭代、反射json结构中每个字段。
Alternatives and performances
与第三方库的性能对比
There are many alternatives in the Go community. ffjson, that is one of them, generates static MarshalJSON and UnmarshalJSON functions that are called from a similar API: ffjson.Marshaland ffjson.Unmarshal. The generated methods look like this:
GitHub上也有很多用于json序列化的第三方库,比如ffjson就是其中之一,ffjson的命令行工具可以为指定的结构生成静态的MarshalJSON和UnmarshalJSON函数,MarshalJSON和UnmarshalJSON函数在序列化和反序列化操作时会分别被ffjson.Marshal和ffjson.Unmarshal函数调用。以下为ffjson生成的解析器示例:
1 | func (j *JSONFF) MarshalJSON() ([]byte, error) { |
Let’s now compare the benchmark between the standard library and ffjson (with usage of ffjson.Pool()):
现在比较一下标准库和ffjson(使用了ffjson.Pool())的性能差异:
1 | standard lib: |
For Marshaling or Unmarshaling, it looks like that the native library is more efficient.
对于json序列化/反序列化,标准库与ffjson相比反而更加高效一些。
Regarding the higher usage of memory, we can see with the compiler go run -gcflags="-m" some variables will be allocated to the heap:
对于内存使用情况(堆分配),可以通过go run -gcflags="-m"命令进行测试:
1 | :46:19: buf escapes to heap |
Let’s have a look at another one: easyjson. It uses the same strategy. Here is the benchmark:
easyjson库也使用了和ffjson同样的策略,以下为基准测试结果:
1 | standard lib: |
This time, it seems than easyjson is much faster, 30% for the Marshalling and almost 2 times faster for the Unmarshalling. Everything make sense if we look at the easyjson.Marshal method provided by the library:
这次,easyjson比标准库更高效些,对于json序列化有30%的性能提升,对于json反序列化性能提升接近2倍。通过阅读easyjson.Marshal的源码,可以发现它高效的原因:
1 | func Marshal(v Marshaler) ([]byte, error) { |
The method MarshalEasyJSON is generated by the library in order to print the JSON:
通过easyjson的命令行工具生成的编码器MarshalEasyJSON方法可用于json序列化:
1 | func easyjson42239ddeEncode(out *jwriter.Writer, in JSON) { |
As we can see, there is no more reflection. The flow is pretty straightforward. Also, the library provide compatibility with the native JSON library:
正如我们所见,这里没有使用反射。整体流程也很简单。而且,easyjson也可以兼容标准库:
1 | func (v JSON) MarshalJSON() ([]byte, error) { |
However, the performances here will be worse than the native library since the native flow will be applied and only this small part of code will be run during the Marshalling.
然而,使用这种兼容标准库的方式进行序列化会比直接使用标准库性能更差,因为在进行json序列化的过程中,标准库依然会通过反射构造encoder,且MarshalJSON中这一段代码也会被执行。
Conclusion
结论
If many efforts have been done on the standard library, it could be never be as fast as a library that dumps the generation of the JSON. The negative points here are that you will have to maintain this code generation and remain dependent on an external library.
Prior to making any decision about switching from the standard library, you should measure how the json Marshalling/Unmarshalling impacts your application and if a gain of performance could drastically improve the performance of your whole application. If it represents only a small percentage, it is maybe not worth it, the standard library is now efficient enough in most of the cases.
无论在标准库上做多少努力,它都不会比通过对明确的json结构生成encoder/decoder的方式性能好。而通过结构生成解析器代码的方式需要生成和维护此代码,并且依赖于外部的库。
在做出使用第三方序列化库替换标准库的决定前,最好先测试下json序列化和反序列化是否是应用的性能瓶颈点,提高json序列化的效率是否能改善应用的性能。如果json序列化和反序列化并不是应用的性能瓶颈点,为了极少的性能提升,付出第三方库的维护成本是不值得的。毕竟,在大多数业务场景下,Go的标准库encoding/json已经足够高效了。